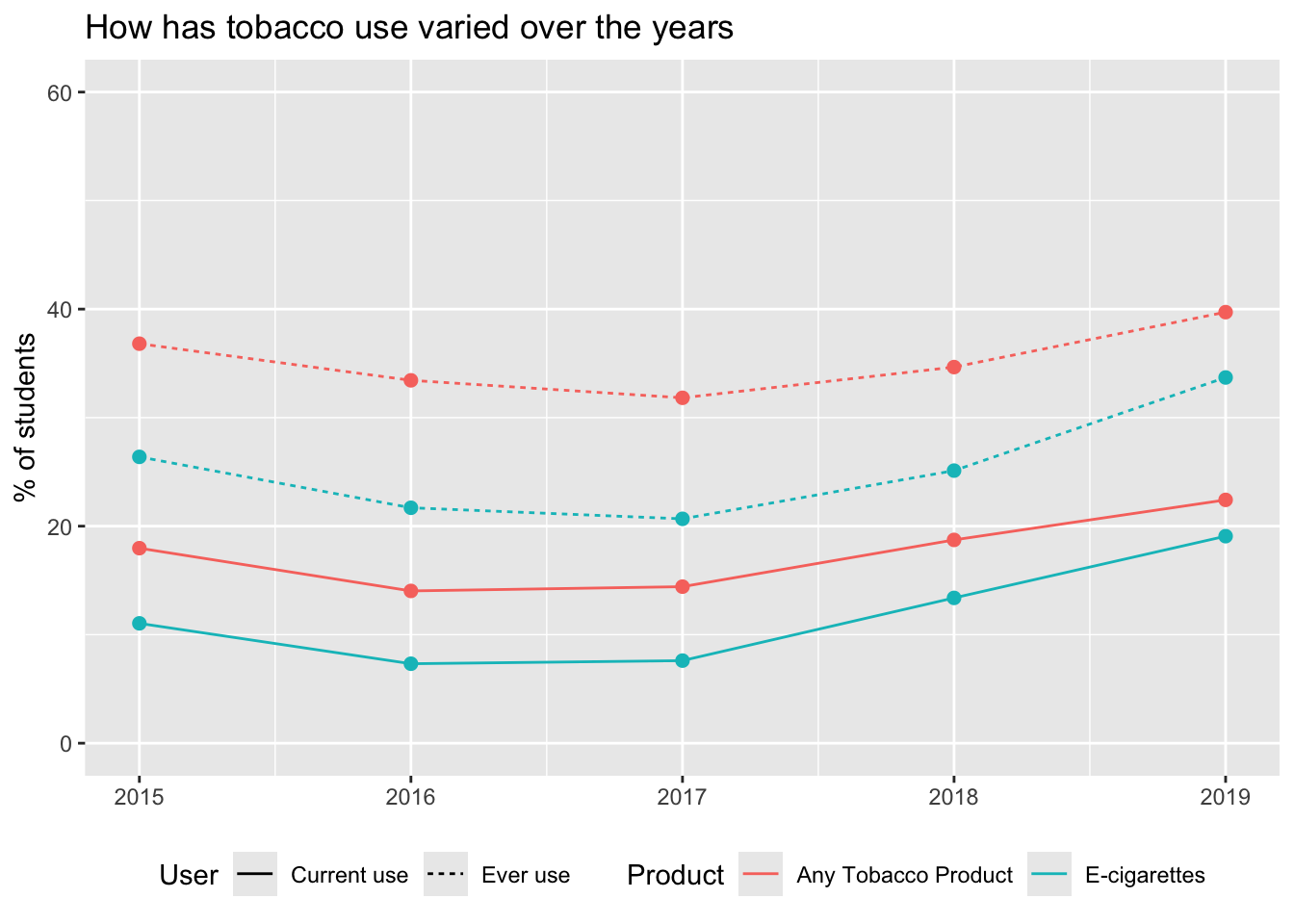
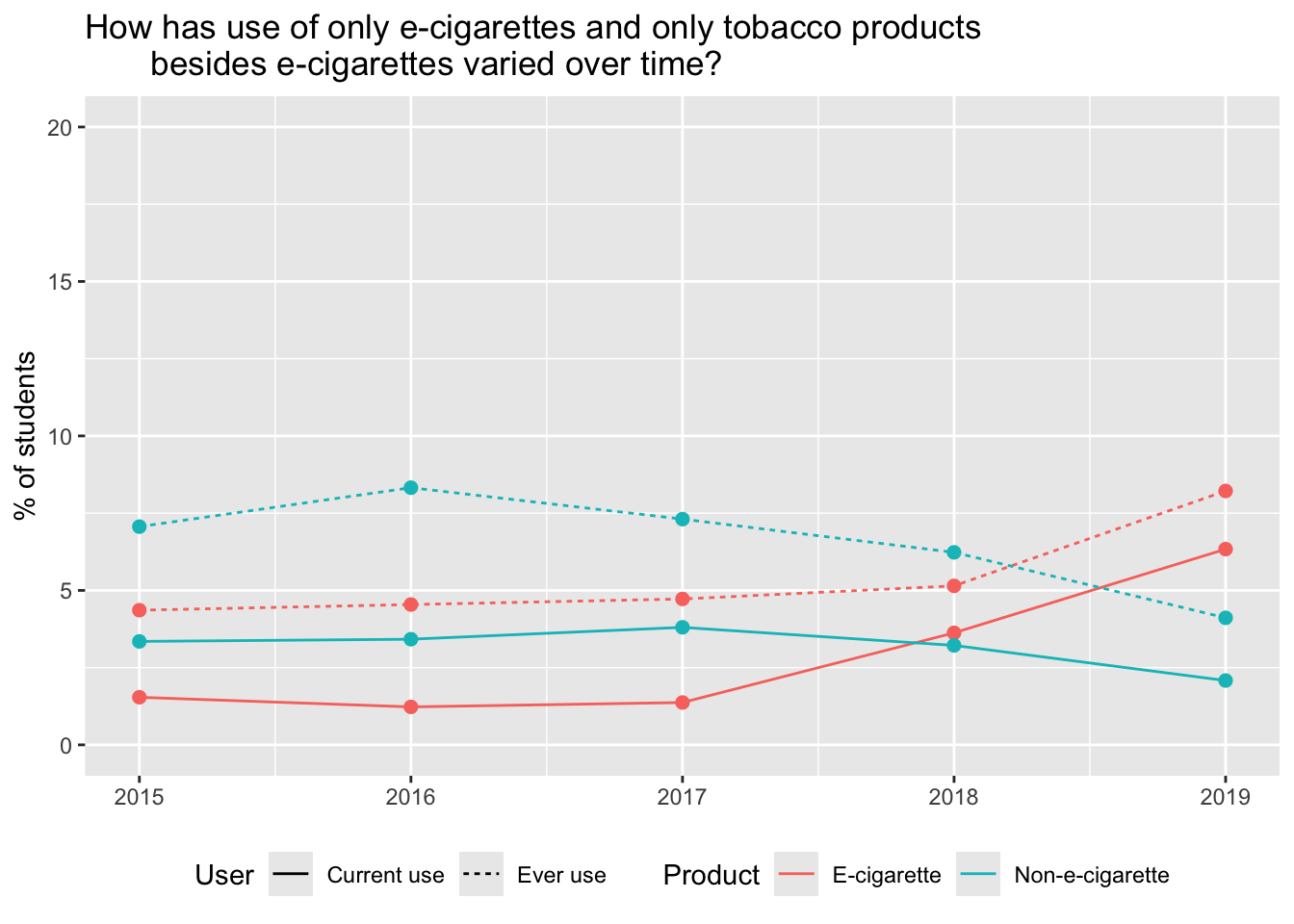
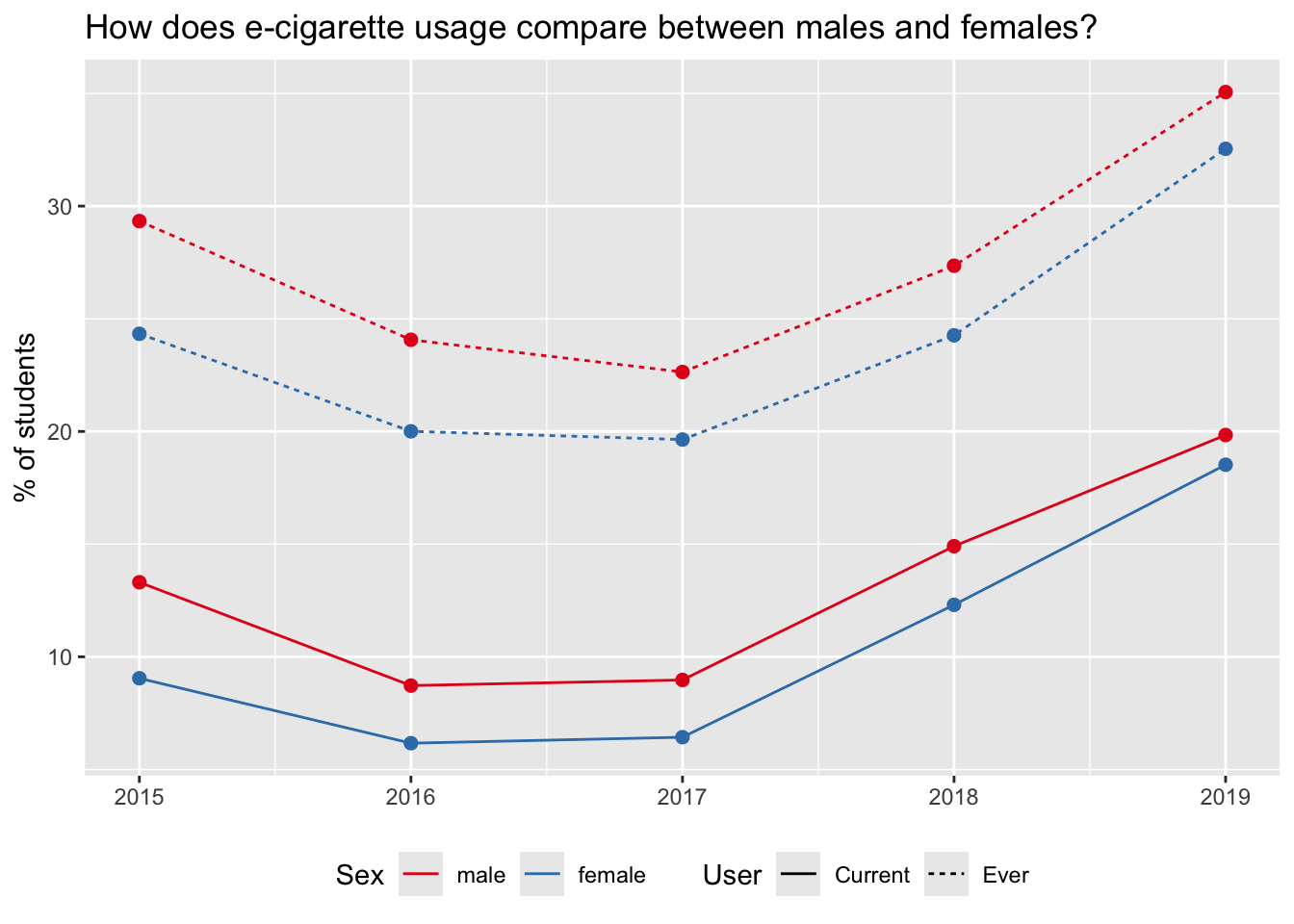
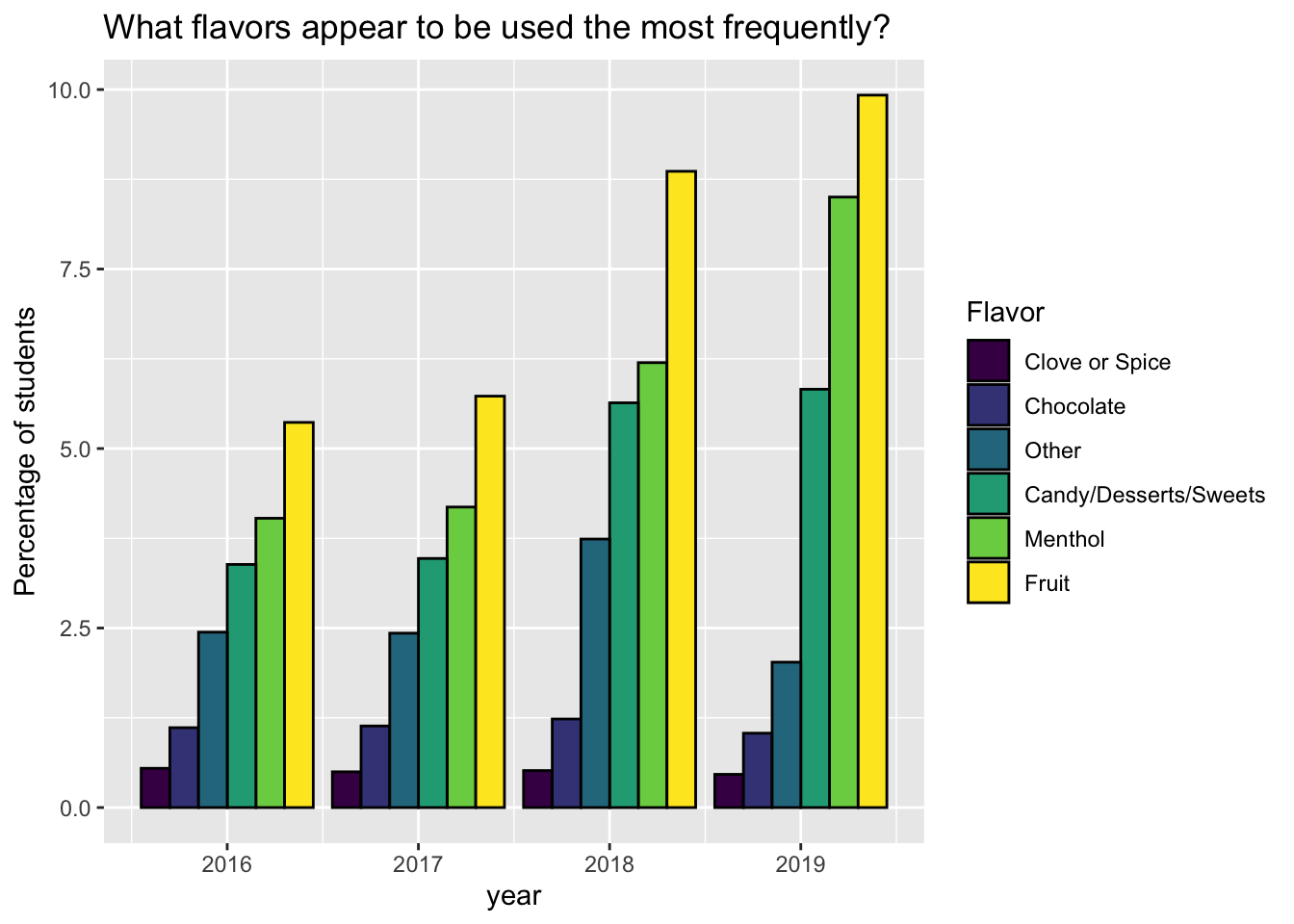
Rows: 95,465
Columns: 59
$ year <dbl> 2015, 2015, 2015, 2015, 2015, 2015, 2015, 2015, …
$ psu <chr> "015438", "015438", "015438", "015438", "015438"…
$ finwgt <dbl> 216.7268, 324.9620, 324.9620, 397.1552, 264.8745…
$ stratum <chr> "BR3", "BR3", "BR3", "BR3", "BR3", "BR3", "BR3",…
$ Age <fct> 18, 17, 18, 18, 18, 18, 18, 18, 18, 18, 18, 18, …
$ Sex <fct> female, male, male, male, female, female, male, …
$ Grade <fct> 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, …
$ ECIGT <lgl> FALSE, TRUE, FALSE, TRUE, FALSE, TRUE, TRUE, TRU…
$ ECIGAR <lgl> TRUE, TRUE, FALSE, FALSE, FALSE, FALSE, TRUE, FA…
$ ESLT <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, …
$ EELCIGT <lgl> FALSE, TRUE, FALSE, TRUE, FALSE, TRUE, TRUE, TRU…
$ EROLLCIGTS <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, …
$ EFLAVCIGTS <lgl> FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, TRUE, F…
$ EBIDIS <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE,…
$ EFLAVCIGAR <lgl> FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, TRUE, F…
$ EHOOKAH <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE,…
$ EPIPE <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE,…
$ ESNUS <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, …
$ EDISSOLV <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE,…
$ CCIGT <lgl> FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, …
$ CCIGAR <lgl> FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, …
$ CSLT <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE,…
$ CELCIGT <lgl> FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, …
$ CROLLCIGTS <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE,…
$ CFLAVCIGTS <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE,…
$ CBIDIS <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE,…
$ CHOOKAH <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE,…
$ CPIPE <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE,…
$ CSNUS <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE,…
$ CDISSOLV <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE,…
$ menthol <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
$ clove_spice <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
$ fruit <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
$ chocolate <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
$ alcoholic_drink <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
$ candy_dessert_sweets <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
$ other <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
$ EHTP <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
$ CHTP <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
$ brand_ecig <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
$ tobacco_sum_ever <dbl> 1, 4, 0, 3, 0, 2, 8, 4, 0, 0, 0, 1, 1, 0, 0, 4, …
$ tobacco_sum_current <dbl> 0, 2, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ tobacco_ever <lgl> TRUE, TRUE, FALSE, TRUE, FALSE, TRUE, TRUE, TRUE…
$ tobacco_current <lgl> FALSE, TRUE, FALSE, TRUE, FALSE, FALSE, FALSE, F…
$ ecig_sum_ever <dbl> 0, 1, 0, 1, 0, 1, 1, 1, 0, 0, 0, 1, 0, 0, 0, 1, …
$ ecig_sum_current <dbl> 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ non_ecig_sum_ever <dbl> 1, 3, 0, 2, 0, 1, 7, 3, 0, 0, 0, 0, 1, 0, 0, 3, …
$ non_ecig_sum_current <dbl> 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ ecig_ever <lgl> FALSE, TRUE, FALSE, TRUE, FALSE, TRUE, TRUE, TRU…
$ ecig_current <lgl> FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, …
$ non_ecig_ever <lgl> TRUE, TRUE, FALSE, TRUE, FALSE, TRUE, TRUE, TRUE…
$ non_ecig_current <lgl> FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, …
$ ecig_only_ever <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE,…
$ ecig_only_current <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE,…
$ non_ecig_only_ever <lgl> TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, …
$ non_ecig_only_current <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE,…
$ no_use <lgl> FALSE, FALSE, TRUE, FALSE, TRUE, FALSE, FALSE, F…
$ Group <chr> "Only other products", "Combination of products"…
$ n <int> 17711, 17711, 17711, 17711, 17711, 17711, 17711,…